Approximation of functions in 2D¶
All the concepts and algorithms developed for approximation of 1D functions \(f(x)\) can readily be extended to 2D functions \(f(x,y)\) and 3D functions \(f(x,y,z)\). Basically, the extensions consists of defining basis functions \({\psi}_i(x,y)\) or \({\psi}_i(x,y,z)\) over some domain \(\Omega\), and for the least squares and Galerkin methods, the integration is done over \(\Omega\).
As in 1D, the least squares and projection/Galerkin methods two lead to linear systems
where the inner product of two functions \(f(x,y)\) and \(g(x,y)\) is defined completely analogously to the 1D case (4.2):
2D basis functions as tensor products of 1D functions¶
One straightforward way to construct a basis in 2D is to combine 1D basis functions. Say we have the 1D vector space
A similar space for variation in \(y\) can be defined,
We can then form 2D basis functions as tensor products of 1D basis functions.
Tensor products
Given two vectors \(a=(a_0,\ldots,a_M)\) and \(b=(b_0,\ldots,b_N)\), their outer tensor product, also called the dyadic product, is \(p=a\otimes b\), defined through
In the tensor terminology, \(a\) and \(b\) are first-order tensors (vectors with one index, also termed rank-1 tensors), and then their outer tensor product is a second-order tensor (matrix with two indices, also termed rank-2 tensor). The corresponding inner tensor product is the well-known scalar or dot product of two vectors: \(p=a\cdot b = \sum_{j=0}^N a_jb_j\). Now, \(p\) is a rank-0 tensor.
Tensors are typically represented by arrays in computer code. In the above example, \(a\) and \(b\) are represented by one-dimensional arrays of length \(M\) and \(N\), respectively, while \(p=a\otimes b\) must be represented by a two-dimensional array of size \(M\times N\).
Tensor products can be used in a variety of context.
Given the vector spaces \(V_x\) and \(V_y\) as defined in (1) and (2), the tensor product space \(V=V_x\otimes V_y\) has a basis formed as the tensor product of the basis for \(V_x\) and \(V_y\). That is, if \(\left\{ {\varphi}_i(x) \right\}_{i\in{\mathcal{I}_x}}\) and \(\left\{ {\varphi}_i(y) \right\}_{i\in {\mathcal{I}_y}}\) are basis for \(V_x\) and \(V_y\), respectively, the elements in the basis for \(V\) arise from the tensor product: \(\left\{ {\varphi}_i(x){\varphi}_j(y) \right\}_{i\in {\mathcal{I}_x},j\in {\mathcal{I}_y}}\). The index sets are \(I_x=\{0,\ldots,N_x\}\) and \(I_y=\{0,\ldots,N_y\}\).
The notation for a basis function in 2D can employ a double index as in
The expansion for \(u\) is then written as a double sum
Alternatively, we may employ a single index,
and use the standard form for \(u\),
The single index is related to the double index through \(i=p (N_y+1) + q\) or \(i=q (N_x+1) + p\).
Example: Polynomial basis in 2D¶
Suppose we choose \(\hat{\psi}_p(x)=x^p\), and try an approximation with \(N_x=N_y=1\):
Using a mapping to one index like \(i=q (N_x+1) + p\), we get
With the specific choice \(f(x,y) = (1+x^2)(1+2y^2)\) on \(\Omega = [0,L_x]\times [0,L_y]\), we can perform actual calculations:
The right-hand side vector has the entries
There is a general pattern in these calculations that we can explore. An arbitrary matrix entry has the formula
where
are matrix entries for one-dimensional approximations. Moreover, \(i=q N_y+q\) and \(j=s N_y+r\).
With \(\hat{\psi}_p(x)=x^p\) we have
and
for \(p,r\in{\mathcal{I}_x}\) and \(q,s\in{\mathcal{I}_y}\).
Corresponding reasoning for the right-hand side leads to
Choosing \(L_x=L_y=2\), we have
Figure Approximation of a 2D quadratic function (left) by a 2D bilinear function (right) using the Galerkin or least squares method illustrates the result.
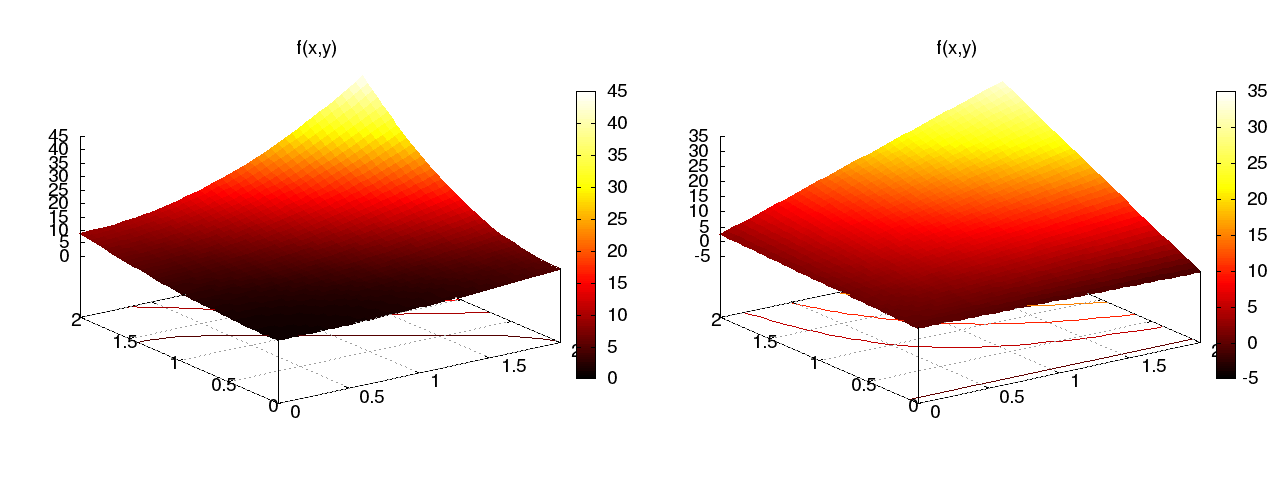
Approximation of a 2D quadratic function (left) by a 2D bilinear function (right) using the Galerkin or least squares method
Implementation (3)¶
The least_squares function from the section Orthogonal basis functions and/or the file approx1D.py can with very small modifications solve 2D approximation problems. First, let Omega now be a list of the intervals in \(x\) and \(y\) direction. For example, \(\Omega = [0,L_x]\times [0,L_y]\) can be represented by Omega = [[0, L_x], [0, L_y]].
Second, the symbolic integration must be extended to 2D:
import sympy as sp
integrand = psi[i]*psi[j]
I = sp.integrate(integrand,
(x, Omega[0][0], Omega[0][1]),
(y, Omega[1][0], Omega[1][1]))
provided integrand is an expression involving the sympy symbols x and y. The 2D version of numerical integration becomes
if isinstance(I, sp.Integral):
integrand = sp.lambdify([x,y], integrand)
I = sp.mpmath.quad(integrand,
[Omega[0][0], Omega[0][1]],
[Omega[1][0], Omega[1][1]])
The right-hand side integrals are modified in a similar way.
Third, we must construct a list of 2D basis functions. Here are two examples based on tensor products of 1D “Taylor-style” polynomials \(x^i\) and 1D sine functions \(\sin((i+1)\pi x)\):
def taylor(x, y, Nx, Ny):
return [x**i*y**j for i in range(Nx+1) for j in range(Ny+1)]
def sines(x, y, Nx, Ny):
return [sp.sin(sp.pi*(i+1)*x)*sp.sin(sp.pi*(j+1)*y)
for i in range(Nx+1) for j in range(Ny+1)]
The complete code appears in approx2D.py.
The previous hand calculation where a quadratic \(f\) was approximated by a bilinear function can be computed symbolically by
>>> from approx2D import *
>>> f = (1+x**2)*(1+2*y**2)
>>> psi = taylor(x, y, 1, 1)
>>> Omega = [[0, 2], [0, 2]]
>>> u, c = least_squares(f, psi, Omega)
>>> print u
8*x*y - 2*x/3 + 4*y/3 - 1/9
>>> print sp.expand(f)
2*x**2*y**2 + x**2 + 2*y**2 + 1
We may continue with adding higher powers to the basis:
>>> psi = taylor(x, y, 2, 2)
>>> u, c = least_squares(f, psi, Omega)
>>> print u
2*x**2*y**2 + x**2 + 2*y**2 + 1
>>> print u-f
0
For \(N_x\geq 2\) and \(N_y\geq 2\) we recover the exact function \(f\), as expected, since in that case \(f\in V\) (see the section Perfect approximation).
Extension to 3D¶
Extension to 3D is in principle straightforward once the 2D extension is understood. The only major difference is that we need the repeated outer tensor product,
In general, given vectors (first-order tensors) \(a^{(q)} = (a^{(q)}_0,\ldots,a^{(q)}_{N_q}\), \(q=0,\ldots,m\), the tensor product \(p=a^{(0)}\otimes\cdots\otimes a^{m}\) has elements
The basis functions in 3D are then
with \(p\in{\mathcal{I}_x}\), \(q\in{\mathcal{I}_y}\), \(r\in{\mathcal{I}_z}\). The expansion of \(u\) becomes
A single index can be introduced also here, e.g., \(i=N_xN_yr + q_Nx + p\), \(u=\sum_i c_i{\psi}_i(x,y,z)\).
Use of tensor product spaces
Constructing a multi-dimensional space and basis from tensor products of 1D spaces is a standard technique when working with global basis functions. In the world of finite elements, constructing basis functions by tensor products is much used on quadrilateral and hexahedra cell shapes, but not on triangles and tetrahedra. Also, the global finite element basis functions are almost exclusively denoted by a single index and not by the natural tuple of indices that arises from tensor products.
