Approximation of functions¶
Let \(V\) be a function space spanned by a set of basis functions \({\psi}_0,\ldots,{\psi}_N\),
such that any function \(u\in V\) can be written as a linear combination of the basis functions:
The index set \({\mathcal{I}_s}\) is defined as \({\mathcal{I}_s} =\{0,\ldots,N\}\) and is used both for compact notation and for flexibility in the numbering of elements in sequences.
For now, in this introduction, we shall look at functions of a single variable \(x\): \(u=u(x)\), \({\psi}_i={\psi}_i(x)\), \(i\in{\mathcal{I}_s}\). Later, we will almost trivially extend the mathematical details to functions of two- or three-dimensional physical spaces. The approximation (1) is typically used to discretize a problem in space. Other methods, most notably finite differences, are common for time discretization, although the form (1) can be used in time as well.
The least squares method (3)¶
Given a function \(f(x)\), how can we determine its best approximation \(u(x)\in V\)? A natural starting point is to apply the same reasoning as we did for vectors in the section Approximation of general vectors. That is, we minimize the distance between \(u\) and \(f\). However, this requires a norm for measuring distances, and a norm is most conveniently defined through an inner product. Viewing a function as a vector of infinitely many point values, one for each value of \(x\), the inner product could intuitively be defined as the usual summation of pairwise components, with summation replaced by integration:
To fix the integration domain, we let \(f(x)\) and \({\psi}_i(x)\) be defined for a domain \(\Omega\subset\mathbb{R}\). The inner product of two functions \(f(x)\) and \(g(x)\) is then
The distance between \(f\) and any function \(u\in V\) is simply \(f-u\), and the squared norm of this distance is
Note the analogy with (2.9): the given function \(f\) plays the role of the given vector \(\boldsymbol{f}\), and the basis function \({\psi}_i\) plays the role of the basis vector \(\boldsymbol{\psi}_i\). We can rewrite (3), through similar steps as used for the result (2.9), leading to
Minimizing this function of \(N+1\) scalar variables \(\left\{ {c}_i \right\}_{i\in{\mathcal{I}_s}}\), requires differentiation with respect to \(c_i\), for all \(i\in{\mathcal{I}_s}\). The resulting equations are very similar to those we had in the vector case, and we hence end up with a linear system of the form (2.10), with basically the same expressions:
The projection (or Galerkin) method¶
As in the section Approximation of general vectors, the minimization of \((e,e)\) is equivalent to
This is known as a projection of a function \(f\) onto the subspace \(V\). We may also call it a Galerkin method for approximating functions. Using the same reasoning as in (2.11)-(2.12), it follows that (6) is equivalent to
Inserting \(e=f-u\) in this equation and ordering terms, as in the multi-dimensional vector case, we end up with a linear system with a coefficient matrix (4) and right-hand side vector (5).
Whether we work with vectors in the plane, general vectors, or functions in function spaces, the least squares principle and the projection or Galerkin method are equivalent.
Example: linear approximation¶
Let us apply the theory in the previous section to a simple problem: given a parabola \(f(x)=10(x-1)^2-1\) for \(x\in\Omega=[1,2]\), find the best approximation \(u(x)\) in the space of all linear functions:
With our notation, \({\psi}_0(x)=1\), \({\psi}_1(x)=x\), and \(N=1\). We seek
where \(c_0\) and \(c_1\) are found by solving a \(2\times 2\) the linear system. The coefficient matrix has elements
The corresponding right-hand side is
Solving the linear system results in
and consequently
Figure Best approximation of a parabola by a straight line displays the parabola and its best approximation in the space of all linear functions.
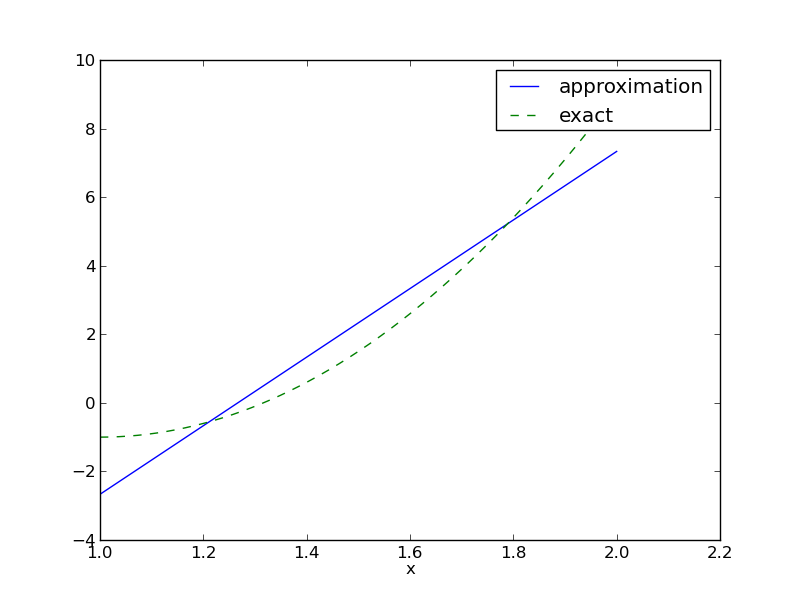
Best approximation of a parabola by a straight line
Implementation of the least squares method¶
The linear system can be computed either symbolically or numerically (a numerical integration rule is needed in the latter case). Here is a function for symbolic computation of the linear system, where \(f(x)\) is given as a sympy expression f involving the symbol x, psi is a list of expressions for \(\left\{ {{\psi}}_i \right\}_{i\in{\mathcal{I}_s}}\), and Omega is a 2-tuple/list holding the limits of the domain \(\Omega\):
import sympy as sp
def least_squares(f, psi, Omega):
N = len(psi) - 1
A = sp.zeros((N+1, N+1))
b = sp.zeros((N+1, 1))
x = sp.Symbol('x')
for i in range(N+1):
for j in range(i, N+1):
A[i,j] = sp.integrate(psi[i]*psi[j],
(x, Omega[0], Omega[1]))
A[j,i] = A[i,j]
b[i,0] = sp.integrate(psi[i]*f, (x, Omega[0], Omega[1]))
c = A.LUsolve(b)
u = 0
for i in range(len(psi)):
u += c[i,0]*psi[i]
return u, c
Observe that we exploit the symmetry of the coefficient matrix: only the upper triangular part is computed. Symbolic integration in sympy is often time consuming, and (roughly) halving the work has noticeable effect on the waiting time for the function to finish execution.
Comparing the given \(f(x)\) and the approximate \(u(x)\) visually is done by the following function, which with the aid of sympy‘s lambdify tool converts a sympy expression to a Python function for numerical computations:
def comparison_plot(f, u, Omega, filename='tmp.pdf'):
x = sp.Symbol('x')
f = sp.lambdify([x], f, modules="numpy")
u = sp.lambdify([x], u, modules="numpy")
resolution = 401 # no of points in plot
xcoor = linspace(Omega[0], Omega[1], resolution)
exact = f(xcoor)
approx = u(xcoor)
plot(xcoor, approx)
hold('on')
plot(xcoor, exact)
legend(['approximation', 'exact'])
savefig(filename)
The modules='numpy' argument to lambdify is important if there are mathematical functions, such as sin or exp in the symbolic expressions in f or u, and these mathematical functions are to be used with vector arguments, like xcoor above.
Both the least_squares and comparison_plot are found and coded in the file approx1D.py. The forthcoming examples on their use appear in ex_approx1D.py.
Perfect approximation¶
Let us use the code above to recompute the problem from the section Example: linear approximation where we want to approximate a parabola. What happens if we add an element \(x^2\) to the basis and test what the best approximation is if \(V\) is the space of all parabolic functions? The answer is quickly found by running
>>> from approx1D import *
>>> x = sp.Symbol('x')
>>> f = 10*(x-1)**2-1
>>> u, c = least_squares(f=f, psi=[1, x, x**2], Omega=[1, 2])
>>> print u
10*x**2 - 20*x + 9
>>> print sp.expand(f)
10*x**2 - 20*x + 9
Now, what if we use \({\psi}_i(x)=x^i\) for \(i=0,1,\ldots,N=40\)? The output from least_squares gives \(c_i=0\) for \(i>2\), which means that the method finds the perfect approximation.
In fact, we have a general result that if \(f\in V\), the least squares and projection/Galerkin methods compute the exact solution \(u=f\). The proof is straightforward: if \(f\in V\), \(f\) can be expanded in terms of the basis functions, \(f=\sum_{j\in{\mathcal{I}_s}} d_j{\psi}_j\), for some coefficients \(\left\{ {d}_i \right\}_{i\in{\mathcal{I}_s}}\), and the right-hand side then has entries
The linear system \(\sum_jA_{i,j}c_j = b_i\), \(i\in{\mathcal{I}_s}\), is then
which implies that \(c_i=d_i\) for \(i\in{\mathcal{I}_s}\).
Ill-conditioning¶
The computational example in the section Perfect approximation applies the least_squares function which invokes symbolic methods to calculate and solve the linear system. The correct solution \(c_0=9, c_1=-20, c_2=10, c_i=0\) for \(i\geq 3\) is perfectly recovered.
Suppose we convert the matrix and right-hand side to floating-point arrays and then solve the system using finite-precision arithmetics, which is what one will (almost) always do in real life. This time we get astonishing results! Up to about \(N=7\) we get a solution that is reasonably close to the exact one. Increasing \(N\) shows that seriously wrong coefficients are computed. Below is a table showing the solution of the linear system arising from approximating a parabola by functions on the form \(u(x)=c_0 + c_1x + c_2x^2 + \cdots + c_{10}x^{10}\). Analytically, we know that \(c_j=0\) for \(j>2\), but numerically we may get \(c_j\neq 0\) for \(j>2\).
| exact | sympy | numpy32 | numpy64 |
|---|---|---|---|
| 9 | 9.62 | 5.57 | 8.98 |
| -20 | -23.39 | -7.65 | -19.93 |
| 10 | 17.74 | -4.50 | 9.96 |
| 0 | -9.19 | 4.13 | -0.26 |
| 0 | 5.25 | 2.99 | 0.72 |
| 0 | 0.18 | -1.21 | -0.93 |
| 0 | -2.48 | -0.41 | 0.73 |
| 0 | 1.81 | -0.013 | -0.36 |
| 0 | -0.66 | 0.08 | 0.11 |
| 0 | 0.12 | 0.04 | -0.02 |
| 0 | -0.001 | -0.02 | 0.002 |
The exact value of \(c_j\), \(j=0,1,\ldots,10\), appears in the first column while the other columns correspond to results obtained by three different methods:
- Column 2: The matrix and vector are converted to the data structure sympy.mpmath.fp.matrix and the sympy.mpmath.fp.lu_solve function is used to solve the system.
- Column 3: The matrix and vector are converted to numpy arrays with data type numpy.float32 (single precision floating-point number) and solved by the numpy.linalg.solve function.
- Column 4: As column 3, but the data type is numpy.float64 (double precision floating-point number).
We see from the numbers in the table that double precision performs much better than single precision. Nevertheless, when plotting all these solutions the curves cannot be visually distinguished (!). This means that the approximations look perfect, despite the partially very wrong values of the coefficients.
Increasing \(N\) to 12 makes the numerical solver in numpy abort with the message: “matrix is numerically singular”. A matrix has to be non-singular to be invertible, which is a requirement when solving a linear system. Already when the matrix is close to singular, it is ill-conditioned, which here implies that the numerical solution algorithms are sensitive to round-off errors and may produce (very) inaccurate results.
The reason why the coefficient matrix is nearly singular and ill-conditioned is that our basis functions \({\psi}_i(x)=x^i\) are nearly linearly dependent for large \(i\). That is, \(x^i\) and \(x^{i+1}\) are very close for \(i\) not very small. This phenomenon is illustrated in Figure The 15 first basis functions , . There are 15 lines in this figure, but only half of them are visually distinguishable. Almost linearly dependent basis functions give rise to an ill-conditioned and almost singular matrix. This fact can be illustrated by computing the determinant, which is indeed very close to zero (recall that a zero determinant implies a singular and non-invertible matrix): \(10^{-65}\) for \(N=10\) and \(10^{-92}\) for \(N=12\). Already for \(N=28\) the numerical determinant computation returns a plain zero.
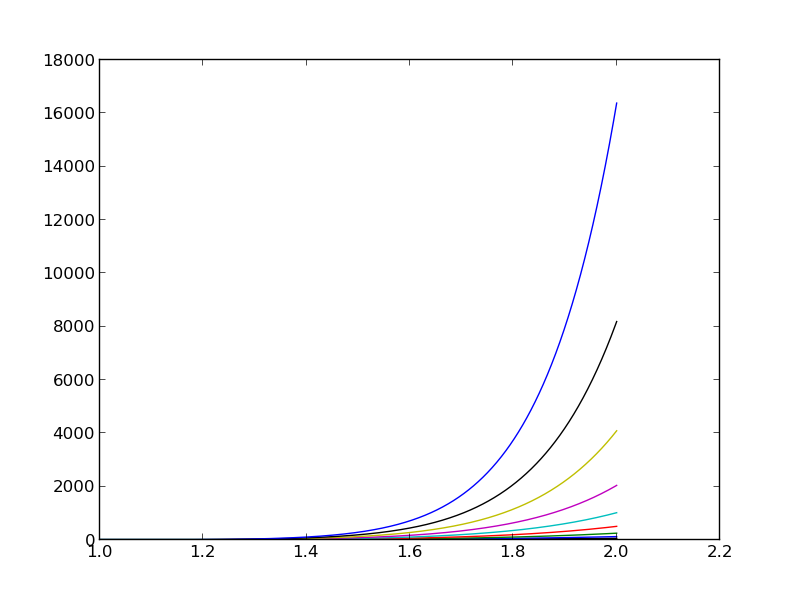
The 15 first basis functions \(x^i\), \(i=0,\ldots,14\)
On the other hand, the double precision numpy solver do run for \(N=100\), resulting in answers that are not significantly worse than those in the table above, and large powers are associated with small coefficients (e.g., \(c_j<10^{-2}\) for \(10\leq j\leq 20\) and \(c<10^{-5}\) for \(j>20\)). Even for \(N=100\) the approximation still lies on top of the exact curve in a plot (!).
The conclusion is that visual inspection of the quality of the approximation may not uncover fundamental numerical problems with the computations. However, numerical analysts have studied approximations and ill-conditioning for decades, and it is well known that the basis \(\{1,x,x^2,x^3,\ldots,\}\) is a bad basis. The best basis from a matrix conditioning point of view is to have orthogonal functions such that \((\psi_i,\psi_j)=0\) for \(i\neq j\). There are many known sets of orthogonal polynomials and other functions. The functions used in the finite element methods are almost orthogonal, and this property helps to avoid problems with solving matrix systems. Almost orthogonal is helpful, but not enough when it comes to partial differential equations, and ill-conditioning of the coefficient matrix is a theme when solving large-scale matrix systems arising from finite element discretizations.
Fourier series¶
A set of sine functions is widely used for approximating functions (the sines are also orthogonal as explained more in the section Ill-conditioning). Let us take
That is,
An approximation to the \(f(x)\) function from the section Example: linear approximation can then be computed by the least_squares function from the section Implementation of the least squares method:
N = 3
from sympy import sin, pi
x = sp.Symbol('x')
psi = [sin(pi*(i+1)*x) for i in range(N+1)]
f = 10*(x-1)**2 - 1
Omega = [0, 1]
u, c = least_squares(f, psi, Omega)
comparison_plot(f, u, Omega)
Figure Best approximation of a parabola by a sum of 3 (left) and 11 (right) sine functions (left) shows the oscillatory approximation of \(\sum_{j=0}^Nc_j\sin ((j+1)\pi x)\) when \(N=3\). Changing \(N\) to 11 improves the approximation considerably, see Figure Best approximation of a parabola by a sum of 3 (left) and 11 (right) sine functions (right).
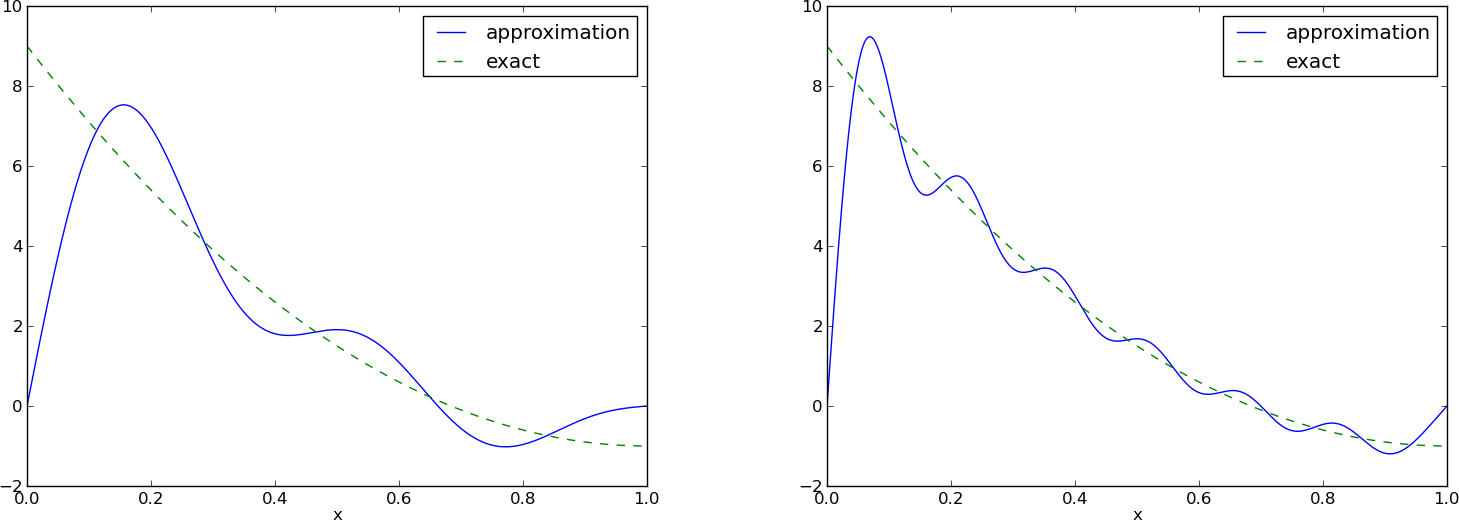
Best approximation of a parabola by a sum of 3 (left) and 11 (right) sine functions
There is an error \(f(0)-u(0)=9\) at \(x=0\) in Figure Best approximation of a parabola by a sum of 3 (left) and 11 (right) sine functions regardless of how large \(N\) is, because all \({\psi}_i(0)=0\) and hence \(u(0)=0\). We may help the approximation to be correct at \(x=0\) by seeking
However, this adjustment introduces a new problem at \(x=1\) since we now get an error \(f(1)-u(1)=f(1)-0=-1\) at this point. A more clever adjustment is to replace the \(f(0)\) term by a term that is \(f(0)\) at \(x=0\) and \(f(1)\) at \(x=1\). A simple linear combination \(f(0)(1-x) + xf(1)\) does the job:
This adjustment of \(u\) alters the linear system slightly as we get an extra term \(-(f(0)(1-x) + xf(1),{\psi}_i)\) on the right-hand side. Figure Best approximation of a parabola by a sum of 3 (left) and 11 (right) sine functions with a boundary term shows the result of this technique for ensuring right boundary values: even 3 sines can now adjust the \(f(0)(1-x) + xf(1)\) term such that \(u\) approximates the parabola really well, at least visually.
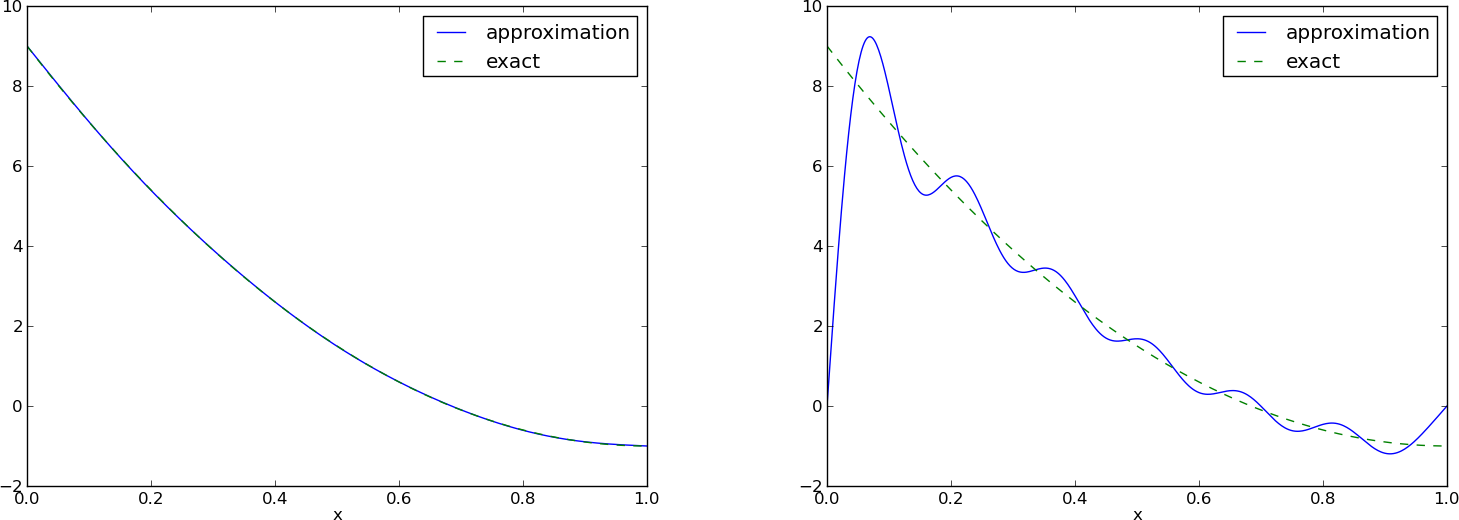
Best approximation of a parabola by a sum of 3 (left) and 11 (right) sine functions with a boundary term
Orthogonal basis functions¶
The choice of sine functions \({\psi}_i(x)=\sin ((i+1)\pi x)\) has a great computational advantage: on \(\Omega=[0,1]\) these basis functions are orthogonal, implying that \(A_{i,j}=0\) if \(i\neq j\). This result is realized by trying
integrate(sin(j*pi*x)*sin(k*pi*x), x, 0, 1)
in WolframAlpha (avoid i in the integrand as this symbol means the imaginary unit \(\sqrt{-1}\)). Also by asking WolframAlpha about \(\int_0^1\sin^2 (j\pi x) {\, \mathrm{d}x}\), we find it to equal 1/2. With a diagonal matrix we can easily solve for the coefficients by hand:
which is nothing but the classical formula for the coefficients of the Fourier sine series of \(f(x)\) on \([0,1]\). In fact, when \(V\) contains the basic functions used in a Fourier series expansion, the approximation method derived in the section Approximation of functions results in the classical Fourier series for \(f(x)\) (see Exercise 8: Fourier series as a least squares approximation for details).
With orthogonal basis functions we can make the least_squares function (much) more efficient since we know that the matrix is diagonal and only the diagonal elements need to be computed:
def least_squares_orth(f, psi, Omega):
N = len(psi) - 1
A = [0]*(N+1)
b = [0]*(N+1)
x = sp.Symbol('x')
for i in range(N+1):
A[i] = sp.integrate(psi[i]**2, (x, Omega[0], Omega[1]))
b[i] = sp.integrate(psi[i]*f, (x, Omega[0], Omega[1]))
c = [b[i]/A[i] for i in range(len(b))]
u = 0
for i in range(len(psi)):
u += c[i]*psi[i]
return u, c
This function is found in the file approx1D.py.
Numerical computations¶
Sometimes the basis functions \({\psi}_i\) and/or the function \(f\) have a nature that makes symbolic integration CPU-time consuming or impossible. Even though we implemented a fallback on numerical integration of \(\int f{\varphi}_i dx\) considerable time might be required by sympy in the attempt to integrate symbolically. Therefore, it will be handy to have function for fast numerical integration and numerical solution of the linear system. Below is such a method. It requires Python functions f(x) and psi(x,i) for \(f(x)\) and \({\psi}_i(x)\) as input. The output is a mesh function with values u on the mesh with points in the array x. Three numerical integration methods are offered: scipy.integrate.quad (precision set to \(10^{-8}\)), sympy.mpmath.quad (high precision), and a Trapezoidal rule based on the points in x.
def least_squares_numerical(f, psi, N, x,
integration_method='scipy',
orthogonal_basis=False):
import scipy.integrate
A = np.zeros((N+1, N+1))
b = np.zeros(N+1)
Omega = [x[0], x[-1]]
dx = x[1] - x[0]
for i in range(N+1):
j_limit = i+1 if orthogonal_basis else N+1
for j in range(i, j_limit):
print '(%d,%d)' % (i, j)
if integration_method == 'scipy':
A_ij = scipy.integrate.quad(
lambda x: psi(x,i)*psi(x,j),
Omega[0], Omega[1], epsabs=1E-9, epsrel=1E-9)[0]
elif integration_method == 'sympy':
A_ij = sp.mpmath.quad(
lambda x: psi(x,i)*psi(x,j),
[Omega[0], Omega[1]])
else:
values = psi(x,i)*psi(x,j)
A_ij = trapezoidal(values, dx)
A[i,j] = A[j,i] = A_ij
if integration_method == 'scipy':
b_i = scipy.integrate.quad(
lambda x: f(x)*psi(x,i), Omega[0], Omega[1],
epsabs=1E-9, epsrel=1E-9)[0]
elif integration_method == 'sympy':
b_i = sp.mpmath.quad(
lambda x: f(x)*psi(x,i), [Omega[0], Omega[1]])
else:
values = f(x)*psi(x,i)
b_i = trapezoidal(values, dx)
b[i] = b_i
c = b/np.diag(A) if orthogonal_basis else np.linalg.solve(A, b)
u = sum(c[i]*psi(x, i) for i in range(N+1))
return u, c
def trapezoidal(values, dx):
"""Integrate values by the Trapezoidal rule (mesh size dx)."""
return dx*(np.sum(values) - 0.5*values[0] - 0.5*values[-1])
Here is an example on calling the function:
from numpy import linspace, tanh, pi
def psi(x, i):
return sin((i+1)*x)
x = linspace(0, 2*pi, 501)
N = 20
u, c = least_squares_numerical(lambda x: tanh(x-pi), psi, N, x,
orthogonal_basis=True)
The interpolation (or collocation) method¶
The principle of minimizing the distance between \(u\) and \(f\) is an intuitive way of computing a best approximation \(u\in V\) to \(f\). However, there are other approaches as well. One is to demand that \(u(x_{i}) = f(x_{i})\) at some selected points \(x_{i}\), \(i\in{\mathcal{I}_s}\):
This criterion also gives a linear system with \(N+1\) unknown coefficients \(\left\{ {c}_i \right\}_{i\in{\mathcal{I}_s}}\):
with
This time the coefficient matrix is not symmetric because \({\psi}_j(x_{i})\neq {\psi}_i(x_{j})\) in general. The method is often referred to as an interpolation method since some point values of \(f\) are given (\(f(x_{i})\)) and we fit a continuous function \(u\) that goes through the \(f(x_{i})\) points. In this case the \(x_{i}\) points are called interpolation points. When the same approach is used to approximate differential equations, one usually applies the name collocation method and \(x_{i}\) are known as collocation points.
Given \(f\) as a sympy symbolic expression f, \(\left\{ {{\psi}}_i \right\}_{i\in{\mathcal{I}_s}}\) as a list psi, and a set of points \(\left\{ {x}_i \right\}_{i\in{\mathcal{I}_s}}\) as a list or array points, the following Python function sets up and solves the matrix system for the coefficients \(\left\{ {c}_i \right\}_{i\in{\mathcal{I}_s}}\):
def interpolation(f, psi, points):
N = len(psi) - 1
A = sp.zeros((N+1, N+1))
b = sp.zeros((N+1, 1))
x = sp.Symbol('x')
# Turn psi and f into Python functions
psi = [sp.lambdify([x], psi[i]) for i in range(N+1)]
f = sp.lambdify([x], f)
for i in range(N+1):
for j in range(N+1):
A[i,j] = psi[j](points[i])
b[i,0] = f(points[i])
c = A.LUsolve(b)
u = 0
for i in range(len(psi)):
u += c[i,0]*psi[i](x)
return u
The interpolation function is a part of the approx1D module.
We found it convenient in the above function to turn the expressions f and psi into ordinary Python functions of x, which can be called with float values in the list points when building the matrix and the right-hand side. The alternative is to use the subs method to substitute the x variable in an expression by an element from the points list. The following session illustrates both approaches in a simple setting:
>>> from sympy import *
>>> x = Symbol('x')
>>> e = x**2 # symbolic expression involving x
>>> p = 0.5 # a value of x
>>> v = e.subs(x, p) # evaluate e for x=p
>>> v
0.250000000000000
>>> type(v)
sympy.core.numbers.Float
>>> e = lambdify([x], e) # make Python function of e
>>> type(e)
>>> function
>>> v = e(p) # evaluate e(x) for x=p
>>> v
0.25
>>> type(v)
float
A nice feature of the interpolation or collocation method is that it avoids computing integrals. However, one has to decide on the location of the \(x_{i}\) points. A simple, yet common choice, is to distribute them uniformly throughout \(\Omega\).
Example (1)¶
Let us illustrate the interpolation or collocation method by approximating our parabola \(f(x)=10(x-1)^2-1\) by a linear function on \(\Omega=[1,2]\), using two collocation points \(x_0=1+1/3\) and \(x_1=1+2/3\):
f = 10*(x-1)**2 - 1
psi = [1, x]
Omega = [1, 2]
points = [1 + sp.Rational(1,3), 1 + sp.Rational(2,3)]
u = interpolation(f, psi, points)
comparison_plot(f, u, Omega)
The resulting linear system becomes
with solution \(c_0=-119/9\) and \(c_1=10\). Figure Approximation of a parabola by linear functions computed by two interpolation points: 4/3 and 5/3 (left) versus 1 and 2 (right) (left) shows the resulting approximation \(u=-119/9 + 10x\). We can easily test other interpolation points, say \(x_0=1\) and \(x_1=2\). This changes the line quite significantly, see Figure Approximation of a parabola by linear functions computed by two interpolation points: 4/3 and 5/3 (left) versus 1 and 2 (right) (right).
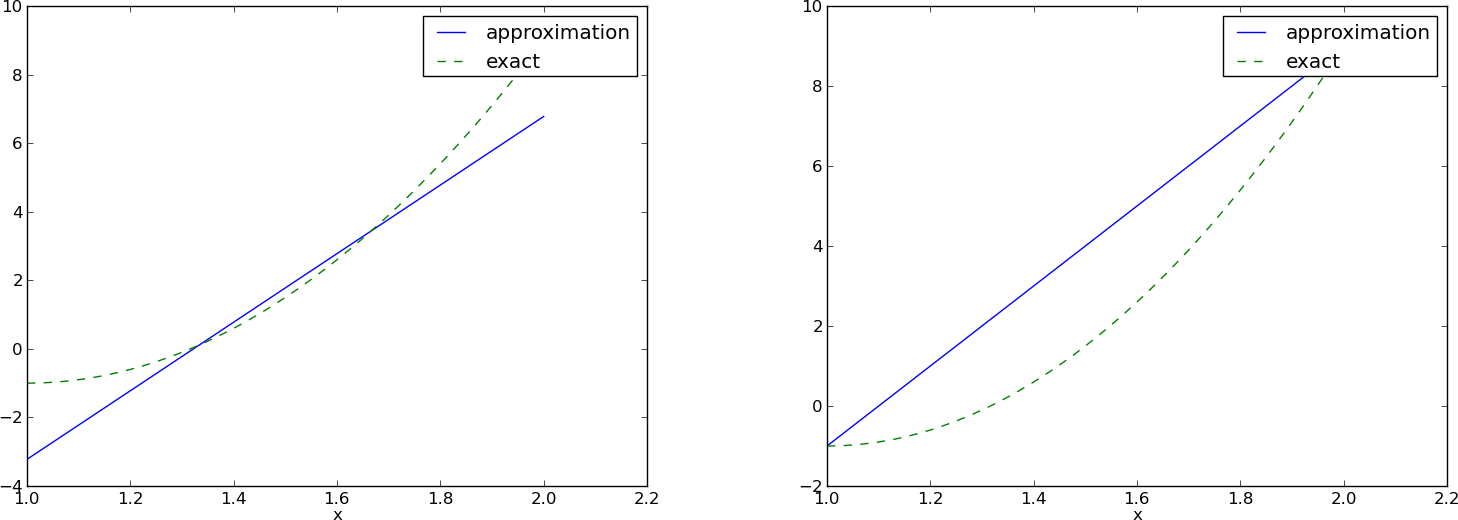
Approximation of a parabola by linear functions computed by two interpolation points: 4/3 and 5/3 (left) versus 1 and 2 (right)
Lagrange polynomials¶
In the section Fourier series we explain the advantage with having a diagonal matrix: formulas for the coefficients \(\left\{ {c}_i \right\}_{i\in{\mathcal{I}_s}}\) can then be derived by hand. For an interpolation/collocation method a diagonal matrix implies that \({\psi}_j(x_{i}) = 0\) if \(i\neq j\). One set of basis functions \({\psi}_i(x)\) with this property is the Lagrange interpolating polynomials, or just Lagrange polynomials. (Although the functions are named after Lagrange, they were first discovered by Waring in 1779, rediscovered by Euler in 1783, and published by Lagrange in 1795.) The Lagrange polynomials have the form
for \(i\in{\mathcal{I}_s}\). We see from (8) that all the \({\psi}_i\) functions are polynomials of degree \(N\) which have the property
when \(x_s\) is an interpolation/collocation point. Here we have used the Kronecker delta symbol \(\delta_{is}\). This property implies that \(A_{i,j}=0\) for \(i\neq j\) and \(A_{i,j}=1\) when \(i=j\). The solution of the linear system is them simply
and
The following function computes the Lagrange interpolating polynomial \({\psi}_i(x)\), given the interpolation points \(x_{0},\ldots,x_{N}\) in the list or array points:
def Lagrange_polynomial(x, i, points):
p = 1
for k in range(len(points)):
if k != i:
p *= (x - points[k])/(points[i] - points[k])
return p
The next function computes a complete basis using equidistant points throughout \(\Omega\):
def Lagrange_polynomials_01(x, N):
if isinstance(x, sp.Symbol):
h = sp.Rational(1, N-1)
else:
h = 1.0/(N-1)
points = [i*h for i in range(N)]
psi = [Lagrange_polynomial(x, i, points) for i in range(N)]
return psi, points
When x is an sp.Symbol object, we let the spacing between the interpolation points, h, be a sympy rational number for nice end results in the formulas for \({\psi}_i\). The other case, when x is a plain Python float, signifies numerical computing, and then we let h be a floating-point number. Observe that the Lagrange_polynomial function works equally well in the symbolic and numerical case - just think of x being an sp.Symbol object or a Python float. A little interactive session illustrates the difference between symbolic and numerical computing of the basis functions and points:
>>> import sympy as sp
>>> x = sp.Symbol('x')
>>> psi, points = Lagrange_polynomials_01(x, N=3)
>>> points
[0, 1/2, 1]
>>> psi
[(1 - x)*(1 - 2*x), 2*x*(2 - 2*x), -x*(1 - 2*x)]
>>> x = 0.5 # numerical computing
>>> psi, points = Lagrange_polynomials_01(x, N=3)
>>> points
[0.0, 0.5, 1.0]
>>> psi
[-0.0, 1.0, 0.0]
The Lagrange polynomials are very much used in finite element methods because of their property (9).
Approximation of a polynomial¶
The Galerkin or least squares method lead to an exact approximation if \(f\) lies in the space spanned by the basis functions. It could be interest to see how the interpolation method with Lagrange polynomials as basis is able to approximate a polynomial, e.g., a parabola. Running
for N in 2, 4, 5, 6, 8, 10, 12:
f = x**2
psi, points = Lagrange_polynomials_01(x, N)
u = interpolation(f, psi, points)
shows the result that up to N=4 we achieve an exact approximation, and then round-off errors start to grow, such that N=15 leads to a 15-degree polynomial for \(u\) where the coefficients in front of \(x^r\) for \(r>2\) are of size \(10^{-5}\) and smaller.
Successful example¶
Trying out the Lagrange polynomial basis for approximating \(f(x)=\sin 2\pi x\) on \(\Omega =[0,1]\) with the least squares and the interpolation techniques can be done by
x = sp.Symbol('x')
f = sp.sin(2*sp.pi*x)
psi, points = Lagrange_polynomials_01(x, N)
Omega=[0, 1]
u = least_squares(f, psi, Omega)
comparison_plot(f, u, Omega)
u = interpolation(f, psi, points)
comparison_plot(f, u, Omega)
Figure Approximation via least squares (left) and interpolation (right) of a sine function by Lagrange interpolating polynomials of degree 3 shows the results. There is little difference between the least squares and the interpolation technique. Increasing \(N\) gives visually better approximations.
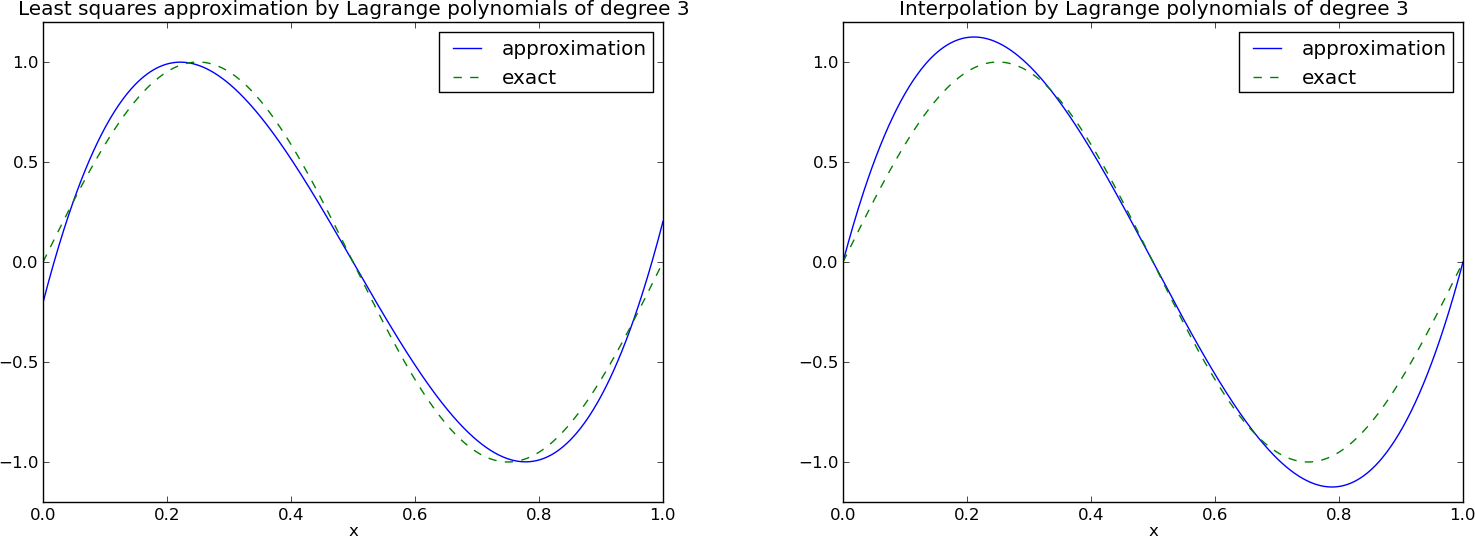
Approximation via least squares (left) and interpolation (right) of a sine function by Lagrange interpolating polynomials of degree 3
Less successful example¶
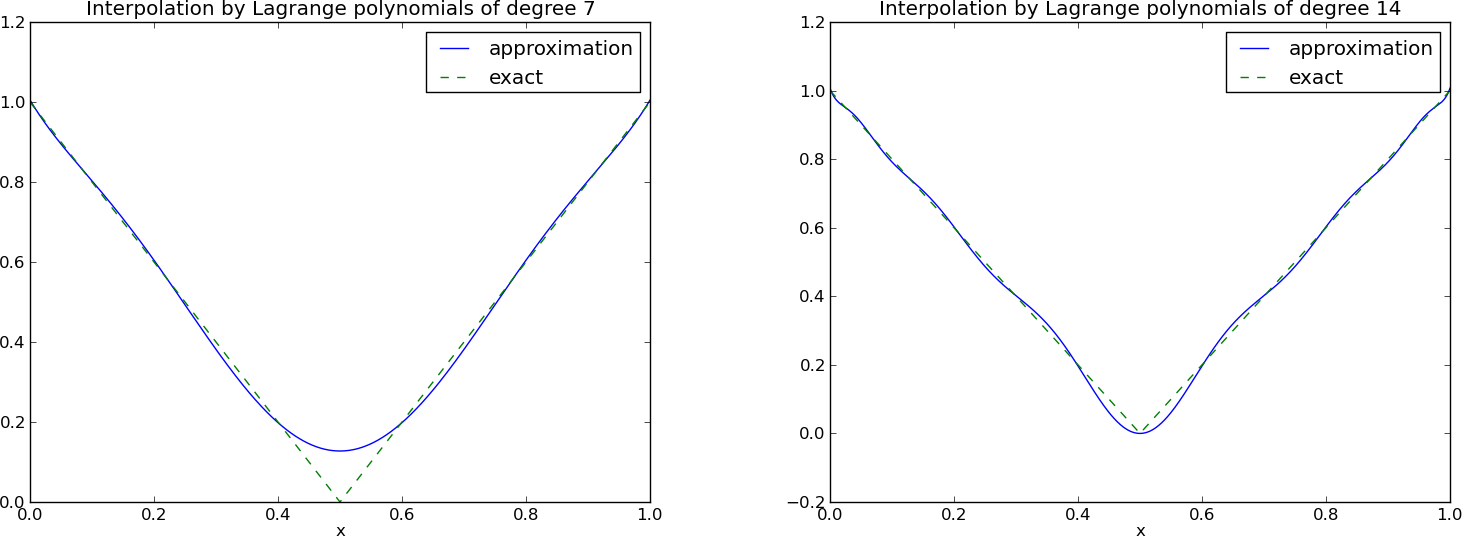
The next example concerns interpolating \(f(x)=|1-2x|\) on \(\Omega =[0,1]\) using Lagrange polynomials. Figure Interpolation of an absolute value function by Lagrange polynomials and uniformly distributed interpolation points: degree 7 (left) and 14 (right) shows a peculiar effect: the approximation starts to oscillate more and more as \(N\) grows. This numerical artifact is not surprising when looking at the individual Lagrange polynomials. Figure Illustration of the oscillatory behavior of two Lagrange polynomials based on 12 uniformly spaced points (marked by circles) shows two such polynomials, \(\psi_2(x)\) and \(\psi_7(x)\), both of degree 11 and computed from uniformly spaced points \(x_{x_i}=i/11\), \(i=0,\ldots,11\), marked with circles. We clearly see the property of Lagrange polynomials: \(\psi_2(x_{i})=0\) and \(\psi_7(x_{i})=0\) for all \(i\), except \(\psi_2(x_{2})=1\) and \(\psi_7(x_{7})=1\). The most striking feature, however, is the significant oscillation near the boundary. The reason is easy to understand: since we force the functions to zero at so many points, a polynomial of high degree is forced to oscillate between the points. The phenomenon is named Runge’s phenomenon and you can read a more detailed explanation on Wikipedia.
Remedy for strong oscillations¶
The oscillations can be reduced by a more clever choice of interpolation points, called the Chebyshev nodes:
on the interval \(\Omega = [a,b]\). Here is a flexible version of the Lagrange_polynomials_01 function above, valid for any interval \(\Omega =[a,b]\) and with the possibility to generate both uniformly distributed points and Chebyshev nodes:
def Lagrange_polynomials(x, N, Omega, point_distribution='uniform'):
if point_distribution == 'uniform':
if isinstance(x, sp.Symbol):
h = sp.Rational(Omega[1] - Omega[0], N)
else:
h = (Omega[1] - Omega[0])/float(N)
points = [Omega[0] + i*h for i in range(N+1)]
elif point_distribution == 'Chebyshev':
points = Chebyshev_nodes(Omega[0], Omega[1], N)
psi = [Lagrange_polynomial(x, i, points) for i in range(N+1)]
return psi, points
def Chebyshev_nodes(a, b, N):
from math import cos, pi
return [0.5*(a+b) + 0.5*(b-a)*cos(float(2*i+1)/(2*N+1))*pi) \
for i in range(N+1)]
All the functions computing Lagrange polynomials listed above are found in the module file Lagrange.py. Figure Interpolation of an absolute value function by Lagrange polynomials and Chebyshev nodes as interpolation points: degree 7 (left) and 14 (right) shows the improvement of using Chebyshev nodes (compared with Figure Interpolation of an absolute value function by Lagrange polynomials and uniformly distributed interpolation points: degree 7 (left) and 14 (right)). The reason is that the corresponding Lagrange polynomials have much smaller oscillations as seen in Figure Illustration of the less oscillatory behavior of two Lagrange polynomials based on 12 Chebyshev points (marked by circles) (compare with Figure Illustration of the oscillatory behavior of two Lagrange polynomials based on 12 uniformly spaced points (marked by circles)).
Another cure for undesired oscillation of higher-degree interpolating polynomials is to use lower-degree Lagrange polynomials on many small patches of the domain, which is the idea pursued in the finite element method. For instance, linear Lagrange polynomials on \([0,1/2]\) and \([1/2,1]\) would yield a perfect approximation to \(f(x)=|1-2x|\) on \(\Omega = [0,1]\) since \(f\) is piecewise linear.
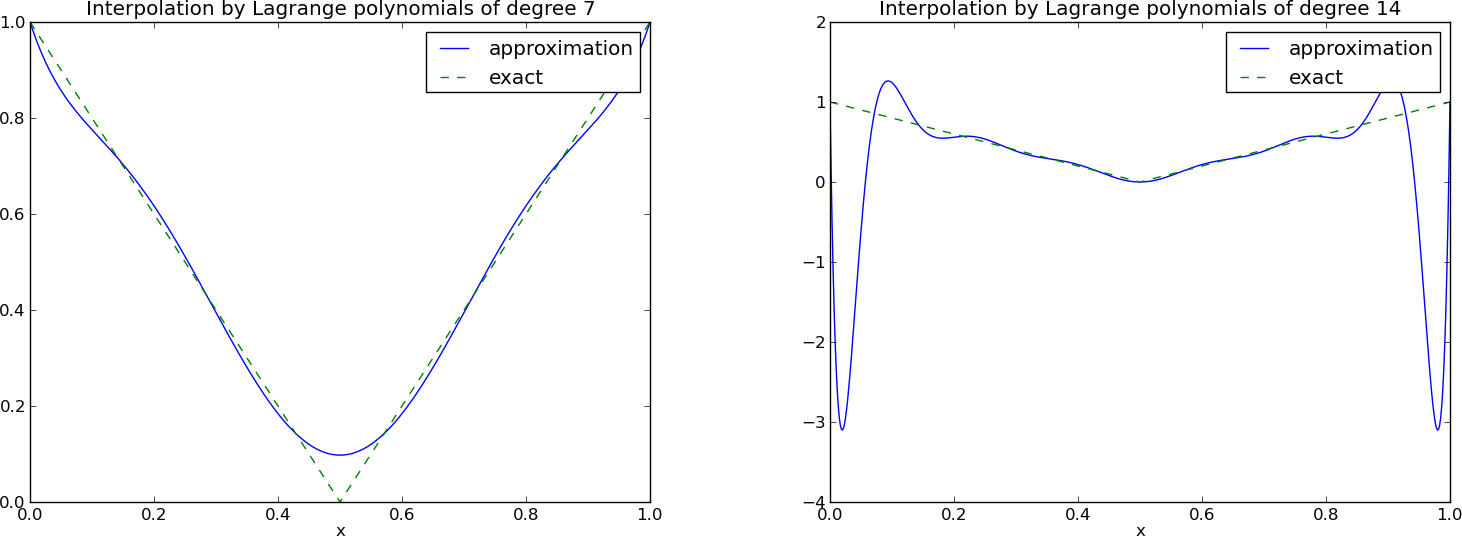
Interpolation of an absolute value function by Lagrange polynomials and uniformly distributed interpolation points: degree 7 (left) and 14 (right)
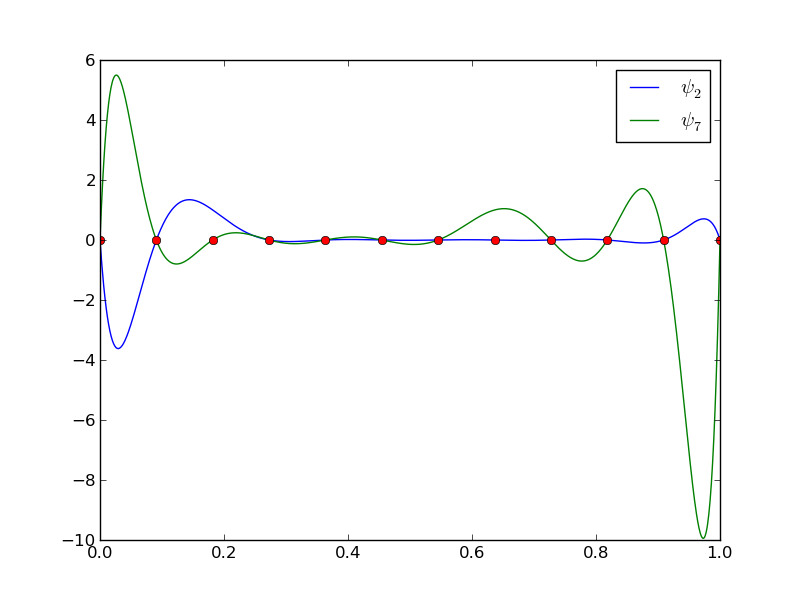
Illustration of the oscillatory behavior of two Lagrange polynomials based on 12 uniformly spaced points (marked by circles)
Interpolation of an absolute value function by Lagrange polynomials and Chebyshev nodes as interpolation points: degree 7 (left) and 14 (right)
Illustration of the less oscillatory behavior of two Lagrange polynomials based on 12 Chebyshev points (marked by circles)
How does the least squares or projection methods work with Lagrange polynomials? Unfortunately, sympy has problems integrating the \(f(x)=|1-2x|\) function times a polynomial. Other choices of \(f(x)\) can also make the symbolic integration fail. Therefore, we should extend the least_squares function such that it falls back on numerical integration if the symbolic integration is unsuccessful. In the latter case, the returned value from sympy‘s integrate function is an object of type Integral. We can test on this type and utilize the mpmath module in sympy to perform numerical integration of high precision. Here is the code:
def least_squares(f, psi, Omega):
N = len(psi) - 1
A = sp.zeros((N+1, N+1))
b = sp.zeros((N+1, 1))
x = sp.Symbol('x')
for i in range(N+1):
for j in range(i, N+1):
integrand = psi[i]*psi[j]
I = sp.integrate(integrand, (x, Omega[0], Omega[1]))
if isinstance(I, sp.Integral):
# Could not integrate symbolically, fallback
# on numerical integration with mpmath.quad
integrand = sp.lambdify([x], integrand)
I = sp.mpmath.quad(integrand, [Omega[0], Omega[1]])
A[i,j] = A[j,i] = I
integrand = psi[i]*f
I = sp.integrate(integrand, (x, Omega[0], Omega[1]))
if isinstance(I, sp.Integral):
integrand = sp.lambdify([x], integrand)
I = sp.mpmath.quad(integrand, [Omega[0], Omega[1]])
b[i,0] = I
c = A.LUsolve(b)
u = 0
for i in range(len(psi)):
u += c[i,0]*psi[i]
return u
![]()
Table Of Contents
- Approximation of functions
- The least squares method (3)
- The projection (or Galerkin) method
- Example: linear approximation
- Implementation of the least squares method
- Perfect approximation
- Ill-conditioning
- Fourier series
- Orthogonal basis functions
- Numerical computations
- The interpolation (or collocation) method
- Lagrange polynomials
Previous topic
Next topic
Finite element basis functions (1)
