This chapter is taken from the book A Primer on Scientific Programming with Python by H. P. Langtangen, 5th edition, Springer, 2016.
Nested lists
Nested lists are list objects where the elements in the lists can be lists themselves. A couple of examples will motivate for nested lists and illustrate the basic operations on such lists.
A table as a list of rows or columns
Our table data have so far used one separate list for each column. If there were \( n \) columns, we would need \( n \) list objects to represent the data in the table. However, we think of a table as one entity, not a collection of \( n \) columns. It would therefore be natural to use one argument for the whole table. This is easy to achieve using a nested list, where each entry in the list is a list itself. A table object, for instance, is a list of lists, either a list of the row elements of the table or a list of the column elements of the table. Here is an example where the table is a list of two columns, and each column is a list of numbers:
Cdegrees = range(-20, 41, 5) # -20, -15, ..., 35, 40
Fdegrees = [(9.0/5)*C + 32 for C in Cdegrees]
table = [Cdegrees, Fdegrees]
(Note that any value
in \( [41,45] \) can be used as second argument (stop value)
to range and will
ensure that 40 is included in the range of generate numbers.)
With the subscript table[0] we can access the
first element in table, which is nothing but the Cdegrees list,
and with table[0][2] we reach
the third element in the first element, i.e.,
Cdegrees[2].
Figure 2: Two ways of creating a table as a nested list. Left: table of columns C and F, where C and F are lists. Right: table of rows, where each row [C, F] is a list of two floats.
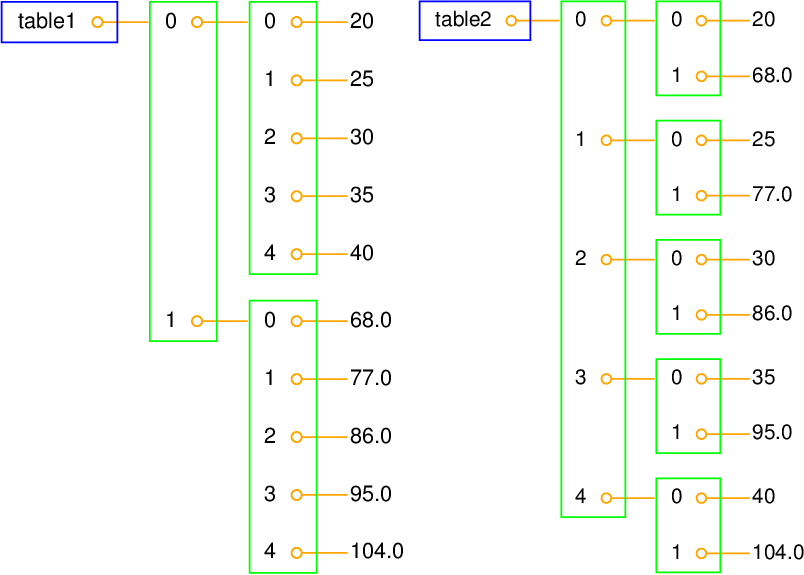
However, tabular data with rows and columns usually have the convention
that the underlying data is a nested list where the first index counts
the rows and the second index counts the columns.
To have table on this form, we must construct table as
a list of [C, F] pairs. The first index will then run over rows
[C, F]. Here is how we may construct the nested list:
table = []
for C, F in zip(Cdegrees, Fdegrees):
table.append([C, F])
We may shorten this code segment by introducing a list comprehension:
table = [[C, F] for C, F in zip(Cdegrees, Fdegrees)]
This construction loops through pairs C and F, and for each pass in
the loop we create a list element [C, F].
The subscript table[1] refers to the second element in table,
which is a [C, F] pair, while table[1][0] is the
C value and table[1][1] is the F value.
Figure 2 illustrates both a list of columns and a list
of pairs. Using this figure, you can realize that the first index looks
up an element in the outer list, and that this element can be indexed
with the second index.
Printing objects
Modules for pretty print of objects
We may write
print table
to immediately view the nested list
table from the previous section. In fact, any Python object obj
can be printed to the screen
by the command print obj.
The output is usually one line, and this line may become very long if the
list has many elements. For example, a long list like our
table variable, demands a quite long line when printed.
[[-20, -4.0], [-15, 5.0], [-10, 14.0], ............., [40, 104.0]]
Splitting the output over several shorter lines makes the
layout nicer and more readable.
The pprint module offers a pretty print functionality for
this purpose. The usage of pprint looks like
import pprint
pprint.pprint(table)
and the corresponding output becomes
[[-20, -4.0], [-15, 5.0], [-10, 14.0], [-5, 23.0], [0, 32.0], [5, 41.0], [10, 50.0], [15, 59.0], [20, 68.0], [25, 77.0], [30, 86.0], [35, 95.0], [40, 104.0]]
With this document comes a slightly modified pprint module having the
name scitools.pprint2. This module
allows full format control of the printing of the float objects
in lists by specifying scitools.pprint2.float_format
as a printf format string. The following example demonstrates how the
output format of real numbers can be changed:
>>> import pprint, scitools.pprint2
>>> somelist = [15.8, [0.2, 1.7]]
>>> pprint.pprint(somelist)
[15.800000000000001, [0.20000000000000001, 1.7]]
>>> scitools.pprint2.pprint(somelist)
[15.8, [0.2, 1.7]]
>>> # default output is '%g', change this to
>>> scitools.pprint2.float_format = '%.2e'
>>> scitools.pprint2.pprint(somelist)
[1.58e+01, [2.00e-01, 1.70e+00]]
As can be seen from this session, the pprint module writes
floating-point numbers with a lot of digits, in fact so many that we
explicitly see the round-off errors. Many find this type of output
is annoying and that the default output from the scitools.pprint2
module is more like one would desire and expect.
The pprint and scitools.pprint2 modules also have a function
pformat, which works as the pprint function, but it returns
a pretty formatted string instead of printing the string:
s = pprint.pformat(somelist)
print s
This last print statement prints the same as pprint.pprint(somelist).
Manual printing
Many will argue that tabular data such as those stored in the
nested table list are not printed in a particularly pretty way
by the pprint module. One would rather expect pretty output to
be a table with two nicely aligned columns. To produce such output we
need to code the formatting manually. This is quite easy: we loop over
each row, extract the two elements C and F in each row,
and print these in fixed-width fields using the printf syntax.
The code goes as follows:
for C, F in table:
print '%5d %5.1f' % (C, F)
Extracting sublists
Python has a nice syntax for extracting parts of a list structure. Such parts are known as sublists or slices:
A[i:] is the sublist starting with index i in A
and continuing to the end of A:
>>> A = [2, 3.5, 8, 10]
>>> A[2:]
[8, 10]
A[i:j] is the sublist starting with index i in A
and continuing up to and including index j-1.
Make sure you remember that the element corresponding to
index j is not included in the sublist:
>>> A[1:3]
[3.5, 8]
A[:i] is the sublist starting with index 0 in A and
continuing up to and including the element with index i-1:
>>> A[:3]
[2, 3.5, 8]
A[1:-1] extracts all elements except the first and the last
(recall that index -1 refers to the last element),
and A[:] is the whole list:
>>> A[1:-1]
[3.5, 8]
>>> A[:]
[2, 3.5, 8, 10]
In nested lists we may use slices in the first index, e.g.,
>>> table[4:]
[[0, 32.0], [5, 41.0], [10, 50.0], [15, 59.0], [20, 68.0],
[25, 77.0], [30, 86.0], [35, 95.0], [40, 104.0]]
We can also slice the second index, or both indices:
>>> table[4:7][0:2]
[[0, 32.0], [5, 41.0]]
Observe that table[4:7] makes a list
[[0, 32.0], [5, 41.0], [10, 50.0]] with three elements.
The slice [0:2] acts on this sublist and picks out its
first two elements,
with indices 0 and 1.
Sublists are always copies of the original list, so if you modify the sublist the original list remains unaltered and vice versa:
>>> l1 = [1, 4, 3]
>>> l2 = l1[:-1]
>>> l2
[1, 4]
>>> l1[0] = 100
>>> l1 # l1 is modified
[100, 4, 3]
>>> l2 # l2 is not modified
[1, 4]
The fact that slicing makes a copy can also be illustrated by the following code:
>>> B = A[:]
>>> C = A
>>> B == A
True
>>> B is A
False
>>> C is A
True
The B == A boolean expression is True if all elements in B
are equal to the corresponding elements in A. The test
B is A is True if A and B are names for the
same list. Setting C = A makes C refer to the same
list object as A, while B = A[:] makes B refer to
a copy of the list referred to by A.
Example
We end this information on sublists by writing
out the part of the table list of [C, F] rows
(see the section Nested lists) where
the Celsius degrees are between 10 and 35 (not including 35):
>>> for C, F in table[Cdegrees.index(10):Cdegrees.index(35)]:
... print '%5.0f %5.1f' % (C, F)
...
10 50.0
15 59.0
20 68.0
25 77.0
30 86.0
You should always stop reading and convince yourself that you understand
why a code segment produces the printed output. In this latter example,
Cdegrees.index(10) returns the index corresponding to the value
10 in the Cdegrees list. Looking at the Cdegrees
elements, one realizes (do it!) that the for loop is equivalent to
for C, F in table[6:11]:
This loop runs over the indices \( 6, 7, \ldots, 10 \) in table.
Traversing nested lists
We have seen that traversing the nested list table could be
done by a loop of the form
for C, F in table:
# process C and F
This is natural code when we know that table is a list of
[C, F] lists.
Now we shall address more general nested
lists where we do not necessarily know how many elements there are
in each list element of the list.
Suppose we use a nested list scores to record the scores of players in
a game: scores[i] holds a list of the historical scores obtained by player
number i. Different players have played the game a different number
of times, so the length of scores[i] depends on i.
Some code may help to make this clearer:
scores = []
# score of player no. 0:
scores.append([12, 16, 11, 12])
# score of player no. 1:
scores.append([9])
# score of player no. 2:
scores.append([6, 9, 11, 14, 17, 15, 14, 20])
The list scores has three elements, each element
corresponding to a player.
The element no. g in the list
scores[p] corresponds to the score obtained in
game number g played by player number p.
The length of the lists scores[p]
varies and equals 4, 1, and 8 for p equal to 0, 1, and 2,
respectively.
In the general case we may have \( n \) players, and some may have played the
game a large number of times, making scores potentially a big
nested list.
How can we traverse the scores list
and write it out in a table format with nicely formatted columns?
Each row in the table corresponds to a player, while columns correspond
to scores.
For example,
the data initialized above can be written out as
12 16 11 12 9 6 9 11 14 17 15 14 20
In a program, we must use
two nested loops, one for the elements
in scores and one for the elements in the sublists of scores.
The example below will make this clear.
There are two basic ways of traversing a nested list: either we use integer indices for each index, or we use variables for the list elements. Let us first exemplify the index-based version:
for p in range(len(scores)):
for g in range(len(scores[p])):
score = scores[p][g]
print '%4d' % score,
print
With the trailing comma after the print string, we avoid a newline so
that the column values in the table (i.e., scores for one player)
appear at the same line. The single print
command after the loop over c adds a newline after each table row.
The reader is encouraged to go through the loops by hand and simulate
what happens in each statement (use the simple scores list initialized
above).
The alternative version where we use variables for iterating over the
elements in the scores list and its sublists looks like this:
for player in scores:
for game in player:
print '%4d' % game,
print
Again, the reader should step through the code by hand and realize what
the values of player and game are in each pass of the loops.
In the very general case, we have a nested list with many indices:
somelist[i1][i2][i3].... To visit each of the elements
in the list, we use as many nested for loops as there are
indices. With four indices, iterating over integer indices look as
for i1 in range(len(somelist)):
for i2 in range(len(somelist[i1])):
for i3 in range(len(somelist[i1][i2])):
for i4 in range(len(somelist[i1][i2][i3])):
value = somelist[i1][i2][i3][i4]
# work with value
The corresponding version iterating over sublists becomes
for sublist1 in somelist:
for sublist2 in sublist1:
for sublist3 in sublist2:
for sublist4 in sublist3:
value = sublist4
# work with value