Strings
Many programs need to manipulate text. For example, when we read the contents of a file into a string or list of strings (lines), we may want to change parts of the text in the string(s) - and maybe write out the modified text to a new file. So far in this document we have converted parts of the text to numbers and computed with the numbers. Now it is time to learn how to manipulate the text strings themselves.
Common operations on strings
Python has a rich set of operations on string objects. Some of the most common operations are listed below.
Substring specification
The expression s[i:j] extracts the
substring starting with character number i
and ending with character number j-1 (similarly to lists, 0 is the
index of the first character):
>>> s = 'Berlin: 18.4 C at 4 pm'
>>> s[8:] # from index 8 to the end of the string
'18.4 C at 4 pm'
>>> s[8:12] # index 8, 9, 10 and 11 (not 12!)
'18.4'
A negative upper index
counts, as usual, from the right such that s[-1] is the last
element, s[-2] is the next last element, and so on.
>>> s[8:-1]
'18.4 C at 4 p'
>>> s[8:-8]
'18.4 C'
Searching for substrings
The call
s.find(s1) returns
the index where
the substring s1 first appears in s. If the substring is
not found, -1 is returned.
>>> s.find('Berlin') # where does 'Berlin' start?
0
>>> s.find('pm')
20
>>> s.find('Oslo') # not found
-1
Sometimes the aim is to just check if a string is contained in another string, and then we can use the syntax:
>>> 'Berlin' in s:
True
>>> 'Oslo' in s:
False
Here is a typical use of the latter construction in an if test:
>>> if 'C' in s:
... print 'C found'
... else:
... print 'no C'
...
C found
Two other convenient methods
for checking if a string starts with or ends with a specified string
are startswith and endswith:
>>> s.startswith('Berlin')
True
>>> s.endswith('am')
False
Substitution
The call
s.replace(s1, s2) replaces substring
s1 by
s2 everywhere in s:
>>> s.replace(' ', '_')
'Berlin:_18.4_C__at_4_pm'
>>> s.replace('Berlin', 'Bonn')
'Bonn: 18.4 C at 4 pm'
A variant of the last example, where several string operations are put together, consists of replacing the text before the first colon:
>>> s.replace(s[:s.find(':')], 'Bonn')
'Bonn: 18.4 C at 4 pm'
Take a break at this point and convince yourself that you understand how we specify the substring to be replaced!
String splitting
The call s.split() splits the string s into words separated by
whitespace (space, tabulator, or newline):
>>> s.split()
['Berlin:', '18.4', 'C', 'at', '4', 'pm']
Splitting a string s into words separated by a text t can be
done by s.split(t). For example, we may split with respect to colon:
>>> s.split(':')
['Berlin', ' 18.4 C at 4 pm']
We know that s contains a city name, a colon, a temperature,
and then C:
>>> s = 'Berlin: 18.4 C at 4 pm'
With s.splitlines(), a multi-line string is split into
lines (very useful when a file has been read into a string and we want
a list of lines):
>>> t = '1st line\n2nd line\n3rd line'
>>> print t
1st line
2nd line
3rd line
>>> t.splitlines()
['1st line', '2nd line', '3rd line']
Upper and lower case
s.lower() transforms all characters to their lower case
equivalents, and s.upper() performs a similar transformation to
upper case letters:
>>> s.lower()
'berlin: 18.4 c at 4 pm'
>>> s.upper()
'BERLIN: 18.4 C AT 4 PM'
Strings are constant
A string cannot be changed, i.e., any change always results in a new string. Replacement of a character is not possible:
>>> s[18] = 5
...
TypeError: 'str' object does not support item assignment
If we want to replace s[18], a new string must
be constructed, for example by keeping the substrings on
either side of s[18] and inserting a '5' in between:
>>> s[:18] + '5' + s[19:]
'Berlin: 18.4 C at 5 pm'
Strings with digits only
One can easily test whether a string contains digits only or not:
>>> '214'.isdigit()
True
>>> ' 214 '.isdigit()
False
>>> '2.14'.isdigit()
False
Whitespace
We can also check if a string contains spaces only by calling the
isspace method.
More precisely, isspace tests for whitespace, which means the
space character, newline, or the TAB character:
>>> ' '.isspace() # blanks
True
>>> ' \n'.isspace() # newline
True
>>> ' \t '.isspace() # TAB
True
>>> ''.isspace() # empty string
False
The isspace is handy for testing for blank lines in files.
An alternative is to strip first and then test for an empty string:
>>> line = ' \n'
>>> line.strip() == ''
True
Stripping off leading and/or trailing spaces in a string is sometimes useful:
>>> s = ' text with leading/trailing space \n'
>>> s.strip()
'text with leading/trailing space'
>>> s.lstrip() # left strip
'text with leading/trailing space \n'
>>> s.rstrip() # right strip
' text with leading/trailing space'
Joining strings
The opposite of the split method is join, which joins elements
in a list of strings with a specified delimiter in between.
That is,
the following two types of statements are inverse operations:
t = delimiter.join(words)
words = t.split(delimiter)
An example on using join may be
>>> strings = ['Newton', 'Secant', 'Bisection']
>>> t = ', '.join(strings)
>>> t
'Newton, Secant, Bisection'
As an illustration of the usefulness of split and join,
we want to remove the first two words on a line.
This task can be done by
first splitting the line into words and then joining the words of interest:
>>> line = 'This is a line of words separated by space'
>>> words = line.split()
>>> line2 = ' '.join(words[2:])
>>> line2
'a line of words separated by space'
There are many more methods in string objects. All methods are described in the String Methods section of the Python Standard Library online document.
Example: Reading pairs of numbers
Problem
Suppose we have a file consisting of pairs of real numbers, i.e., text of the form \( (a,b) \), where \( a \) and \( b \) are real numbers. This notation for a pair of numbers is often used for points in the plane, vectors in the plane, and complex numbers. A sample file may look as follows:
(1.3,0) (-1,2) (3,-1.5)
(0,1) (1,0) (1,1)
(0,-0.01) (10.5,-1) (2.5,-2.5)
The file can be found as read_pairs1.dat. Our task is to read this
text into a nested list pairs such that pairs[i] holds the pair
with index i, and this pair is a tuple of two float objects. We
assume that there are no blanks inside the parentheses of a pair of
numbers (we rely on a split operation, which would otherwise not work).
Solution
To solve this programming problem, we can read in the file line by line; for each line: split the line into words (i.e., split with respect to whitespace); for each word: strip off the parentheses, split with respect to comma, and convert the resulting two words to floats. Our brief algorithm can be almost directly translated to Python code:
# Load the file into list of lines
with open('read_pairs1.dat', 'r') as infile:
lines = infile.readlines()
# Analyze the contents of each line
pairs = [] # list of (n1, n2) pairs of numbers
for line in lines:
words = line.split()
for word in words:
word = word[1:-1] # strip off parenthesis
n1, n2 = word.split(',')
n1 = float(n1); n2 = float(n2)
pair = (n1, n2)
pairs.append(pair) # add 2-tuple to last row
This code is available in the file
read_pairs1.py.
The width statement is the modern Python way of reading files,
with the advantage that we do not need to think about closing the file.
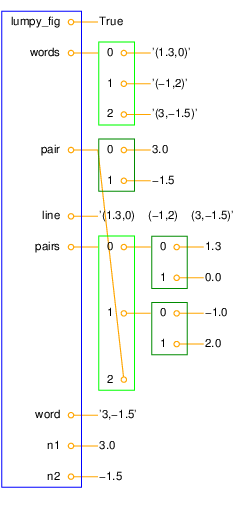
Figure 3 shows a snapshot of the state of the
variables in the program after having treated the first line.
You should explain each line in the program to yourself, and
compare your understanding with the figure.
Figure 3: Illustration of the variables in the read_pairs.py program after the first pass in the loop over words in the first line of the data file.
The output from the program becomes
[(1.3, 0.0), (-1.0, 2.0), (3.0, -1.5), (0.0, 1.0), (1.0, 0.0), (1.0, 1.0), (0.0, -0.01), (10.5, -1.0), (2.5, -2.5)]
We remark that our solution to this programming problem relies heavily on the fact that spaces inside the parentheses are not allowed. If spaces were allowed, the simple split to obtain the pairs on a line as words would not work. What can we then do?
We can first strip off all blanks on a line, and then observe that the
pairs are separated by the text ')('. The first and last pair on a
line will have an extra parenthesis that we need to remove. The rest
of code is similar to the previous code and can be found in
read_pairs2.py:
with open('read_pairs2.dat', 'r') as infile:
lines = infile.readlines()
# Analyze the contents of each line
pairs = [] # list of (n1, n2) pairs of numbers
for line in lines:
line = line.strip() # remove whitespace such as newline
line = line.replace(' ', '') # remove all blanks
words = line.split(')(')
# strip off leading/trailing parenthesis in first/last word:
words[0] = words[0][1:] # (-1,3 -> -1,3
words[-1] = words[-1][:-1] # 8.5,9) -> 8.5,9
for word in words:
n1, n2 = word.split(',')
n1 = float(n1); n2 = float(n2)
pair = (n1, n2)
pairs.append(pair)
The program can be tested on the file read_pairs2.dat:
(1.3 , 0) (-1 , 2 ) (3, -1.5)
(0 , 1) ( 1, 0) ( 1 , 1 )
(0,-0.01) (10.5,-1) (2.5, -2.5)
A third approach is to notice that if the pairs were separated by commas,
(1, 3.0), (-1, 2), (3, -1.5) (0, 1), (1, 0), (1, 1)
the file text is very close to the Python syntax of a list of 2-tuples. By adding enclosing brackets, plus a comma at the end of each line,
[(1, 3.0), (-1, 2), (3, -1.5), (0, 1), (1, 0), (1, 1),]
we have a string to which we can apply eval to get the pairs list
directly. Here is the code doing this (program read_pairs3.py):
with open('read_pairs3.dat', 'r') as infile:
listtext = '['
for line in infile:
# add line, without \n (line[:-1]), with a trailing comma:
listtext += line[:-1] + ', '
listtext = listtext + ']'
pairs = eval(listtext)
In general, it is a good idea to construct file formats that are as close
as possible to valid Python syntax such that one can take advantage
of the eval or exec functions to turn text into "live objects".
Example: Reading coordinates
Problem
Suppose we have a file with coordinates \( (x,y,z) \) in three-dimensional space. The file format looks as follows:
x=-1.345 y= 0.1112 z= 9.1928
x=-1.231 y=-0.1251 z= 1001.2
x= 0.100 y= 1.4344E+6 z=-1.0100
x= 0.200 y= 0.0012 z=-1.3423E+4
x= 1.5E+5 y=-0.7666 z= 1027
The goal is to read this file and create a list with (x,y,z)
3-tuples, and thereafter convert the nested list to a two-dimensional
array with which we can compute.
Note that there is sometimes a space between the = signs and the
following number and sometimes not. Splitting with respect to space and
extracting every second word is therefore not an option.
We shall present three solutions.
Solution 1: substring extraction
The file format looks very regular with the x=, y=,
and z= texts starting in the same columns at every line.
By counting characters, we realize that the x= text starts
in column 2, the y= text starts in column 16, while the
z= text starts in column 31. Introducing
x_start = 2
y_start = 16
z_start = 31
the three numbers in a line string are obtained as the substrings
x = line[x_start+2:y_start]
y = line[y_start+2:z_start]
z = line[z_start+2:]
The following code, found in file
file2coor_v1.py,
creates the coor array with shape \( (n,3) \),
where \( n \) is the number of \( (x,y,z) \) coordinates.
infile = open('xyz.dat', 'r')
coor = [] # list of (x,y,z) tuples
for line in infile:
x_start = 2
y_start = 16
z_start = 31
x = line[x_start+2:y_start]
y = line[y_start+2:z_start]
z = line[z_start+2:]
print 'debug: x="%s", y="%s", z="%s"' % (x,y,z)
coor.append((float(x), float(y), float(z)))
infile.close()
import numpy as np
coor = np.array(coor)
print coor.shape, coor
The print statement inside the loop
is always wise to include when doing string manipulations,
simply
because counting indices for substring limits quickly leads to errors.
Running the program, the output from the loop looks like this
debug: x="-1.345 ", y=" 0.1112 ", z=" 9.1928 "
for the first line in the file. The double quotes show the exact
extent of the extracted coordinates. Note that the last quote
appears on the next line. This is because line has a newline
at the end (this newline must be there to define the end of the line),
and the substring line[z_start:] contains the newline at the
of line. Writing line[z_start:-1] would leave the
newline out of the \( z \) coordinate. However, this has no effect in
practice since we transform the substrings to float, and an extra
newline or other blanks make no harm.
The coor object at the end of the program has the value
[[ -1.34500000e+00 1.11200000e-01 9.19280000e+00] [ -1.23100000e+00 -1.25100000e-01 1.00120000e+03] [ 1.00000000e-01 1.43440000e+06 -1.01000000e+00] [ 2.00000000e-01 1.20000000e-03 -1.34230000e+04] [ 1.50000000e+05 -7.66600000e-01 1.02700000e+03]]
Solution 2: string search
One problem with the solution approach above is that the program
will not work if the file format is subject to a
change in the
column positions of x=, y=, or z=.
Instead of hardcoding numbers for the column positions, we can use
the find method in string objects to locate these column positions:
x_start = line.find('x=')
y_start = line.find('y=')
z_start = line.find('z=')
The rest of the code is similar to the complete program listed above, and the complete code is stored in the file file2coor_v2.py.
Solution 3: string split
String splitting is a powerful tool, also in the present case. Let us split with respect to the equal sign. The first line in the file then gives us the words
['x', '-1.345 y', ' 0.1112 z', ' 9.1928']
We throw away the first word, and strip off the last character in the next word. The final word can be used as is. The complete program is found in the file file2coor_v3.py and looks like
infile = open('xyz.dat', 'r')
coor = [] # list of (x,y,z) tuples
for line in infile:
words = line.split('=')
x = float(words[1][:-1])
y = float(words[2][:-1])
z = float(words[3])
coor.append((x, y, z))
infile.close()
import numpy as np
coor = np.array(coor)
print coor.shape, coor
More sophisticated examples of string operations appear in the section Example: Extracting data from HTML.